Asynchronous BOFs: Enabling New Use Cases for Red Team Operators
The introduction of Beacon Object Files (BOFs) by Cobalt Strike in 2020 revolutionized the capabilities of red team operators and developers, offering a standardized interface for operator code to run within, and interact with, an implant. However, the current BOF standard was designed for synchronous operations, limiting its potential applications.
Asynchronous BOFs Execution Would Enable New Red Team Capabilities
Within this blog Cornelis (@Cneelis) and I introduce the concept and initial design of real-time monitoring for events (e.g. sleep until an admin logs in, sleep until a user starts his password vault) for Beacon Object Files. This new asynchronous design allows operators to roll out a network of sensors and stream these events to the C2 server for further processing – all while the implant is sleepmasked. The server can in turn queue automated tasks, such as downsleeping, asking a TGT (and periodically renewing it) or starting a keylogger.
Background
Within Outflank Security Tooling (OST), we offer both a collection of tradecraft (including BOFs) and a custom implant. At Outflank we constantly try to innovate and push boundaries of existing technologies.
One of the areas we are experimenting with for a while is asynchronous Beacon Object Files, and this blog will share some insights into our journey so far.
Note: At this point in time, we are not sharing a specification or code samples. This is because the server and implant-side API specifications can change as we are in the midst of our research journey and first want to collect feedback.
Our Research Journey
Where it Started
During our operations we regularly encounter shortcomings of the current BOF implementation. In large customer environments where modern security solutions (NGAV/EDR) are used, it might be OPSEC expensive/risky to perform process injection, so we prefer to stay in the process. However, unfortunately not all BOF tools that we use (think of domain/share enumeration tools or monitoring tools) are suitable to run for a longer/indefinite period without the implant itself temporarily not responding anymore.
Additionally, a long running BOF task will prevent the implant from going into (deep) sleep, keeping it visible in memory and showing an unbacked thread stack. This can cause OPSEC risks with current EDR solutions.
In short, the current BOF standard was initially designed for synchronous operations, limiting its potential applications. This is due to the design; the BOF makes function calls to the implant code (text section) every time a Beacon (i.e. BeaconPrintf) function is called. If done from a separate thread, while the implant is sleeping with a sleepmask enabled, the process will crash.
Brainstorming on Asynchronous BOFs
To get around these problems we started looking at a solution where we can make BOF execution asynchronous. The most basic idea is to run BOF tools in the background and still be able to use our implant. As soon as new data is available from the BOF, this data should seamlessly pass on to the server (console) and as soon as the BOF is done with its task everything is cleaned up nicely by the implant.
In one of the whiteboard-sessions we identified a need for stopping tasks and waking up the implant from within the BOF code. We liked the idea and started further exploring.
At RedTreat 2024 (an invite-only conference) we presented and discussed a first version of asynchronous BOFs. We’ve since then refined the design and ideas.
Use Case: Monitoring the Compromised Endpoint for an Admin Login
After various research discussions, we identified the following use case:
“An operator should have a capability to instruct an implant to sleep until an admin logs in on the infected machine, and once the admin logs-in the implant should check-in instantly to relay this information”.
This capability would allow an operator to be:
- More time-efficient: No need to manually monitor or spend time on checking and waiting for an event to occur on the infected machine.
- More stealth: as the implant is sleeping and preventing unnecessary check-ins / network communication there is less detection risk.
- More reliable: you are sure to not miss the event, even if an event only lasts a couple of minutes or occurs outside of office hours.
- More effective: instant check-in once the specific event occurs instead of waiting ‘until the next sleep interval’ making it much more likely that you are ‘on-time’ to execute your next action. Additionally, if combined with pre-programmed response actions, it would be possible to extract the value (i.e., credentials, etc) of an event in order to continue later (i.e., after the weekend).
Once this use case works, we can imagine the following situation:
Example Scenario
Imagine a reasonably well designed and tiered (+clean source) environment from a target organisation that already experienced multiple (3+) Red Team engagements. In this example, their environment is not perfect, so for admin / business purposes, there is a brief tier violation.
A highly privileged admin / service account only logs in for a couple of minutes every week on a shared / lower tier workstation. Obtaining these credentials/tickets would rule out any manual monitoring. We need to monitor and react to user logon events. This asynchronous task will wake the implant up at every new/interesting logon. The implant will relay each newly logged on username to the server. On the server is a task that handles the output of this monitoring job. The server can queue automated tasks if a tier violation is detected or if the user is in the whitelist / not on the blacklist, etc. These tasks can include downsleeping, asking a TGT (and periodically renewing it), injecting into a process, starting a keylogger or running an AskCreds BOF to spawn a popup asking for the admin’s credentials. Additionally, operators can also be notified.
Once all preparations are done, this automation can be lightning fast. It can take less than one or two seconds from the user logging in, to newly scheduled tasks running on that user’s context. This level of automations is very welcome – and sometimes even “lifesaving” – for difficult Red Teaming operations where opportunities present themselves very rarely.

Asynchronous Workload Use Cases
Besides the ‘monitor for an admin login’ example above we noticed that insight into unexpected or infrequent events can be the deciding factor in difficult Red Teaming engagements where important opportunities present themselves infrequently and/or have a short opportunity window.
1. Event Monitoring
We identified various scenarios where a ‘monitoring’ capability could be of help, some of our thoughts:
- Alert on specific processes starts (e.g. password vault, specific business applications).
- Logoff notifications (and pausing the process shut down for a few seconds) allows operators to place Just-In-Time persistence.
- Likewise, EDR network isolation or manual endpoint investigation could allow the implant to perform a process exit to prevent investigation.
- User login (local or remote) could trigger credential/ticket dumping.
- A website visit could trigger a cookie dump.
- New VPN or Company Wi-Fi connections.
- Nearly expired Kerberos tickets can be renewed.
The real value of asynchronous tasks lies (in our opinion) in continuous monitoring and alerting tasks, especially if combined with automatic implant wakeup and pre-programmed response actions. Actions, such as starting a keylogger, dumping credentials/tickets or monitoring the clipboard could be sufficient to make the most out of an event. Even if such an event unexpectedly occurs outside of business hours / weekend, it could be sufficient to profit later.
Next to these (indefinite) monitoring tasks, there are two more categories that are supported.
2. Long Running Task
The simplest example is to take a normal task or BOF that has a long execution time. This provides the least amount of benefit to the operator but is easiest to support:
- SprayAD – password spraying a large amount of AD users.
- BloodHound / SharpHound – collecting large amounts of data from AD.
- PrivEsc checks.
This would allow an operator to continue interacting with the implant while a longer BOF is running, avoiding ‘wait time’ when active behind keyboard.
3. OPSEC Risk Management
Another variant is to take a normal BOF that performs an OPSEC risky action and might trigger an EDR memory scan. For example:
- Credential dumping.
- Process injection.
Running these tasks asynchronous allows the implant to be sleepmasked during risky actions – effectively avoiding memory scans. This might be especially suitable for heavily signatured implants.
The Point
Theory vs. Practice
With today’s Command and Control frameworks it is already possible to execute some rudimentary monitoring functionality. For example, an operator could run ‘monitoring alike functionality’ with the Rubeus /monitor command.
However, such solutions have major drawbacks such as:
- A large convenience burden (no event alerting, no capabilities to stop tasks).
- A high OPSEC risk (implant not sleeping or dropping executables on disk).
Our research about monitoring and async BOFs is not about making it theoretically possible, but practically usable.
To allow operators to develop and use event monitoring use-cases, it is important that a C2 framework provides an OPSEC safe and convenient way for async workloads use by natively supporting them.
The design proposed below provides arguably no tangible OPSEC risks while providing the same convenience as running regular BOFs. As an operator, I would even opt for running one or more monitoring BOFs on initial implant check-in – something previously unimaginable.
Design
To maximize usability and to prevent reinventing the wheel, we reuse as much as possible from the current industry standard Command & Control design.
Our requirements are:
- Operators should be able develop their own monitoring use-cases, rooted around the BOF format.
- The C2 framework and implant should abstract away some of the ‘inner workings’ of signaling.
- The C2 framework and implant should provide sufficient support for running and stopping these Async BOFs in a safe, scalable and stable manner.
- The C2 framework’s existing server-side scripting language should be used for further automation.
A simple architecture diagram is shown below. It is roughly the same as normal BOF execution. Basically, the BOF communicates with the cna/python automations over a C2 communication channel.


In the diagram below, you can see the execution contexts of an implant, a BOF and an Async BOF. During a check-in cycle, the implant can perform tasks, such as running BOFs. During sleep, the implant is sleep masked. This is why an Async BOF cannot directly call the Beacon functions (such as BeaconPrintf) from the implant. The solution is to copy/merge/link a subset of the Beacon functions into the Async BOF when loading it.
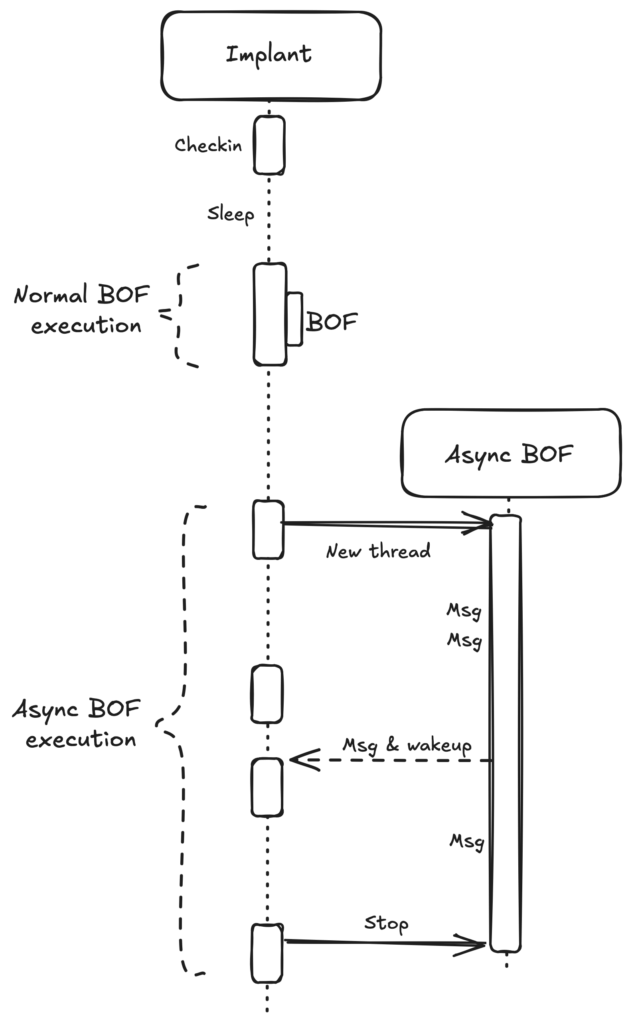
Synchronization
Since we are now working with multiple execution contexts (threads), we need to implement the standard thread synchronization features. These inner workings should be abstracted away in the implant as they are not important to operators / BOF devs. However, as you saw in the diagram above, there are two synchronization features or building blocks we’d like to expose to Async BOF developers:
- A wakeup signal for the BOF to signal the implant to wake up.
- A stop signal for the implant to signal the BOF to stop.
While the other synchronization features can be abstracted away, these two building blocks require implant and BOF interaction. Let’s discuss these two building blocks.
Wake Implant Up on Event: Sleepmasks!
The necessity of implant wake-up originated from recognizing the possible scale of operations. Responsive event propagation at scale requires either a low sleep setting, causing a lot of check-ins or a wakeup mechanism.
A mechanism can be used by the async task to wake the implant up to send an important message to the server. The wake-up mechanism can be very simple. Modern implants have sleepmasks which already support the use of events. Implementations usually wait for a (self-created) event with a timeout to facilitate the sleep. Simply sharing the sleepmask wake up event with the asynchronous task is sufficient to make this work.
It is theoretically possible to implement this by creating a named event in a sleepmask and use the same named event in the Async BOF. However, this results in all kind of complexities with versioning, compatibility, event names and OPSEC risks.
In our current implementation we’ve decided that a BOF developer should not be bothered with the inner working of the sleepmask, as that could tie a BOF to a specific sleepmask resulting in all kind of complexities with versioning, compatibility, event names and OPSEC risks. Practically, to make this usable and OPSEC safe, it is best that the implant manages this event.
The wake-up functionality is facilitated by the implant. A BOF can call the BeaconWakeup() function that signals the sleep mask event:
DECLSPEC_IMPORT void BeaconWakeup();
A Stop Mechanism
From an implant developer perspective, the easiest way to implement task/job stop functionality is by running the task in a separate thread and simply killing the entire thread instead of stopping it. While possible, it is not ideal since creating threads is OPSEC risky / not preferred. Furthermore, crashes can occur if a callback or WMI sink was registered by the monitoring BOF. Lastly, it leads to memory leaks and thus possibly higher risk of YARA / signature detections during the process lifetime.
A better alternative OPSEC wise would be to use the thread pool, but killing a thread pool thread can easily result in crashing the entire process.
To facilitate a gentile stop, we need a stop signal of some sorts that is sent from the implant towards the BOF, and once the signal is received the async BOF should nicely stop itself.
For that we introduce the:
DECLSPEC_IMPORT HANDLE BeaconGetStopJobEvent();
function which will return a HANDLE to an event that is signaled when the task should stop running. This is easy to integrate:
- If the async BOF uses wait for single event, it can easily be changed to wait for multiple events to allow seamless integration of this functionality.
- If the async BOF performs checks in a loop with a sleep, it can be changed to use a wait for single event with a timeout instead of the sleep.
This mechanism allows us to prevent memory leaks and improve our OPSEC by using alternative execution contexts, such as the thread pool and maintain stability.
Handling of a Monitoring Event
Once a monitored event occurs, the monitor BOF can put data (e.g. the username of the admin that is logging in) into a message and wake-up the implant. The regular communications and job architecture ensure that the message is sent towards the team server. Using existing scripting capabilities (e.g. .cna and .py) a developer or operator could set-up post-event actions (e.g. down sleep and dump Kerberos tickets).
Having at least some automation capability is nice, because unlike normal BOFs, events do not occur at a moment of our choice. It is useful to have the ability to automatically queue tasks to capture the value of that event.
Seeing it in Action
The first demo from our implementation in Outflank C2 (part of our OST offering) shows how it is possible to monitor for a specific user – waking up the implant when the condition occurs. Thereafter, we show how to monitor for a specific process.
The second demo shows how a keylogger and clipboard monitor can be used to attack the use of a password manager.
Future Vision
With the above architecture and features, Red Teams can start to roll out a network of sensors in their target environment. These sensors stream events to the server which in turn processes them and react when needed.
Maybe in the future, operators roll out such a monitoring network that there will be a need for more powerful log aggregation and processing solutions, essentially rolling out a lightweight, offensive Security Information and Event Management (SIEM) solution into the target environment. This in turn allows operators to (more effectively) take advantage of opportunities and save (a lot of) time.
Additionally, by creating server-side automations, it will be possible to share knowledge responses and workflows in case an interesting event is observed.
We hope that luck will be less of a factor in future operations, by pre-automating event responses. This will improve the quality and consistency of Red Team operations.
Conclusion
This blog described the ideas, design elements and future vision of monitoring BOFs. We hope that these blogs inspires professionals and move the offensive security conversation forward.
If you have feedback or thoughts on this, feel free to reach out. We are currently running experiments within OST, as well as collaborating with Cobalt Strike on the future of Async and monitoring BOFs.
If you’re not an OST customer but are interested in learning more about our async BOF implementation, we recommend scheduling an expert led demo to learn more.